Les f-chaînes¶
L’essentiel¶
La problématique des chaînes formatées¶
Le formatage de chaînes est une possibilité offerte par de nombreux langages de programmation de créer une chaîne de caractères (comprendre du texte) à partir d’un modèle prédéfini. Typiquement, on peut utiliser le formatage de chaîne pour générer une date en français puisqu’une telle date a la structure jj/mm/aaaa connue à l’avance ou encore l’heure qui a le format hh:mm:ss. Mais, au-delà de ces formats figés, de nombreuses compositions structurées comme un sudoku à remplir, une table de conjugaison ou un calendrier :
Janvier 2038
di lu ma me je ve sa
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
31
sont avantageusement construites en utilisant des chaînes formatées.
La notion de chaîne formatée¶
Supposons qu’on veuille générer de façon automatisée des phrases ayant la structure suivante :
Son nom est titi et il a 8 ans.
Son nom est Arthur et il a 30 ans.
Son nom est Alfred et il a 100 ans.
D’une phrase à l’autre, seuls le nom et le nombre représentant l’âge changent. Les chaînes ci-dessus sont dites des chaînes formatées : toutes les chaînes ont même structure, ici de la forme
Son nom est XXX et il a YYY ans.
Seuls varient le nom XXX et l’âge YYY.
Dans le présent document j’appelerai la chaîne-modèle telle que
Son nom est XXX et il a YYY ans.
un gabarit ou encore un modèle ou parfois une chaîne de formatage. Les parties à remplacer sont appelées champs de remplacement (en anglais remplacement field). Un gabarit est le modèle à partir duquel d’autres chaînes vont être produites par substitution.
Les f-chaînes : exemple typique¶
La version 3.6 de Python a introduit une simplification syntaxique très intéressante pour le formatage de chaînes : les chaînes littérales formatées ou encore les f-string (en français, les f-chaînes, terme que j’emploierai). Un simple exemple montre bien la lisibilité de cette syntaxe :
1 2 3 4 | nom = "Arthur"
age = 30
s = f"Son nom est {nom} et il a {age + 10} ans"
print(s)
|
5 | Son nom est Arthur et il a 40 ans
|
Elles ont l’apparence de chaînes littérales habituelles, cf. les quotes ligne 3, mais elles sont précédées d’une lettre f (pour « formaté »). Dans la chaîne littérale, entre accolades, on place une expression Python (et pas seulement une variable) et le remplacement se fait après évaluation de l’expression. Ci-dessus, noter que l’expression age + 10 a été évaluée.
Pour des situations simples et dans de nombreuses situations courantes, les f-chaînes fournissent la méthode la plus souple et la plus lisible pour effectuer un formatage de chaînes. En interne, elles utilisent la méthode format dont elles reprennent largement la syntaxe. La méthode format est plus générale mais, peut-être, moins lisible.
Documentation¶
- Lien vers la documentation officielle : Formatted string literals
- Discussions sur stackoverflow : python, fstring
Spécification de formatage dans une f-chaîne¶
Jusqu’à présent un champ de remplacement (ie une paire d’accolades) dans une f-chaîne, contient uniquement une expression :
1 2 3 4 | fruits = ["pomme", "poire", "prune"]
s = f"une {fruits[1]}, une {fruits[2]} et une {fruits[1]}"
print(s)
|
5 | une poire, une prune et une poire
|
- Ligne 2 : chaque champ de remplacement contient juste une expression.
Mais, cette syntaxe peut être enrichie pour préciser dans chaque champ de remplacement une spécification de formatage, par exemple ici comment on formate une date :
1 2 3 4 5 6 7 | jsemaine = "dimanche"
mois = 9
jmois = 1
an =2030
s = f"{jsemaine} {jmois:02}/{mois:02}/{an}"
print(s)
|
8 | dimanche 01/09/2030
|
- Ligne 6 : on compte 4 champs de remplacement (les 4 paires d’accolades) ; le 2e et le 3e contiennent une spécification de formatage. Par exemple, dans le champ
{jmois:02}, la partie02à droite du symbole:est une spécification de formatage.
À droite du nom du champ, il est possible de placer un « spécification de formatage » qui précise comment la valeur à substituer doit être formatée. Pour signifier une spécification de formatage, après le nom du champ, on place le symbole : (deux-points) ; la spécification de formatage suit le symbole : jusqu’à l’accolade fermante.
En pratique, une spécification de formatage sert surtout à formater des nombres suivant leurs types (entiers, décimaux, etc) et à gérer l’espacement autour du champ de remplacement.
Reprenons l’exemple précédent :
1 2 3 4 5 6 7 | jsemaine = "dimanche"
mois = 9
jmois = 1
an =2030
s = f"{jsemaine} {jmois:02}/{mois:02}/{an}"
print(s)
|
8 | dimanche 01/09/2030
|
- Ligne 1 : par exemple, le champ
{jmois:02}signifie (ce sera expliqué en détail ultérieurement) que la valeur dejmoisdoit être un nombre et qu’il sera formaté en plaçant un zéro devant le nombre si le nombre n’est constitué que d’un seul chiffre. - Ligne 8 :
jmoisqui vaut9comme on le voit ligne 2, est donc formaté sous la forme09.
Spécificateurs de formatage¶
Précisons maintenant ce qu’on entend par « spécificateurs de formatage » :
1 2 3 4 5 6 7 | jsemaine = "dimanche"
mois = 9
jmois = 1
an =2030
s = f"{jsemaine} {jmois:02}/{mois:02}/{an}"
print(s)
|
8 | dimanche 01/09/2030
|
Ligne 6 :
02est une spécification de formatage. En réalité, cette spécification se décompose en deux « spécificateurs » :- le spécificateur
0pour spécifier que le nombre est, si nécessaire, précédé de zéros ; - le spécificateur
2pour spécifier que deux chiffres seront représentés, cf. le09de l’affichage.
- le spécificateur
Plus généralement, chaque spécification est constituée d’une succession de spécificateurs, jusqu’à 8 spécificateurs. On prendra soin de ne pas placer par mégarde d’espaces dans la spécification, après les deux points sinon l’espace sera visible, voire aura un effet inattendu :
1 2 3 4 5 6 7 | jsemaine = "dimanche"
mois = 9
jmois = 1
an =2030
s = f"{jsemaine} {jmois:02}/{mois: 02}/{an}"
print(s)
|
8 | dimanche 01/ 9/2030
|
- Ligne 6 : on a rajouté un espace dans l’avant-dernière accolade, juste avant le
02 - Ligne 8 : le zéro a disparu avant le
2et a été remplacé par un un espace.
Par ailleurs, l’ordre des spécificateurs n’est pas sans importance. Au lieu de spécificateur, le terme d’option de formatage est aussi employé, et parfois aussi de spécifieur (anglicisme).
Les règles s’appliquant à une spécification de formatage utilisée par les f-chaines sont les mêmes que celles utilisées pour les gabarits de la méthode format.
Partie décimale d’un flottant dans une f-chaîne¶
Le formatage des valeurs des flottants en Python peut faire apparaître jusqu’à 6 décimales. Le programmeur souhaite parfois n’en faire apparaître qu’un nombre plus réduit (ou plus important). Une spécificateur dit de précision permet de contrôler le nombre de chiffres décimaux nécessaires pour représenter un nombre flottant donné :
1 2 3 4 5 | x=22/7
print(x)
print(f"{x:.2f}")
print(f"{x:.50f}")
|
6 7 8 | 3.142857142857143
3.14
3.14285714285714279370154144999105483293533325195312
|
Ligne 4 : la spécification est ici
.2fet contient deux spécificateurs :- point suivi de la valeur de la précision (un entier positif)
- le type
f(pour flottant)
Ligne 7 : l’approximation donnée est incorrecte, par défaut, on ne peut pas espérer plus d’une quinzaine de chiffres significatifs corrects.
Même comportement si le nombre à formater est de type entier ou s’il possède moins de chiffres significatif que la précision demandée :
x=42.5
print(x)
print(f"{x:.2f}")
x=42
print(x)
print(f"{x:.2f}")
42.5
42.50
42
42.00
La représentation obtenue avec le spécificateur de précision est un arrondi et non pas une troncature, autrement dit, c’est la valeur la plus proche du nombre et ayant le nombre de chiffres indiqué qui est retenue :
1 2 3 4 | x=2/3
print(x)
print(f"{x:.2f}")
|
5 6 | 0.6666666666666666
0.67
|
- Ligne 6 : si le formatage avait tronqué la valeur, le résultat aurait été
0.66.
Échappement des accolades dans une f-chaîne¶
L’accolade est un caractère typographique utilisé dans certains domaines. Par exemple, en mathématiques, le contenu d’un ensemble est représenté en le plaçant entre deux accolades. Ainsi, \(E=\{42,421\}\) est l’ensemble formé de deux éléments 42 et 421.
Ainsi, on peut se demander comment, par exemple, créer une f-chaîne qui affiche un ensemble mathématique ayant deux éléments ? La réponse est que pour représenter une accolade dans une f-chaîne, on double l’accolade (ce qu’on appelle un échappement) :
a = 42
b = 421
s=f"E = {{{10*a}, {b}}}"
print(s)
E = {420, 421}
- Ligne 3 : les deux premières accolades permettent de désigner la première accolade ligne 6 ; la paire d’accolade qui suit (
{10*a}) est un champ de remplacement qui permet de placer l’élément420de la ligne 2. De même pour{b}qui place \(\mathtt{421}\).
Quelques possibilités et limitations des f-chaînes¶
Le problème du séparateur de chaîne littérale¶
Comme pour des chaînes littérales, un caractère apostrophe ou guillemet appartenant à la chaîne, comme le guillemet dans l’exemple ci-dessous :
La fable "Le loup et l'agneau" de la Fontaine
peut entrer en collision avec le délimiteur de la chaîne. On NE peut PAS y remédier en échappant le quote avec une contre-oblique mais on peut y remédier :
- soit en changeant de quote (c’est rarement impossible),
- soit en utilisant une variable temporaire.
Ainsi :
x=3
# changement de quote
s = f"{'Pomme'*x}"
print(s)
# variable
fruit = "Pomme"
s = f"{fruit * x}"
print(s)
PommePommePomme
PommePommePomme
Le problème du backslash¶
L’expression à évaluer ne peut pas contenir de vrai backslash litteral :
print(f"Le nombre Pi : { '\u03C0'}")
print(f"Le nombre Pi : { '\u03C0'}")
^
SyntaxError: f-string expression part cannot include a backslash
même si le backslah est une continuation de ligne dans une chaîne triple :
s = f"""{x+\
1}"""
1}"""
SyntaxError: f-string expression part cannot include a backslash
Pour y remédier, on utilise une variable temporaire :
pi = "\u03C0"
print(f"Le nombre Pi : {pi}")
Le nombre Pi : π
Toutefois, une double contre-oblique est possible (pour échapper la contre-oblique donc) :
nom= "pascal"
s = f"Dossier C:\\User\\{nom}"
print(s)
Dossier C:\User\pascal
Le problème du symbole deux-points (:)¶
Les expressions lambda peuvent poser un problème syntaxique car elles contiennent un caractère : qui sert à introduire une spécification de formatage. On peut néanmoins employer des expressions lambda à condition qu’elles soient entourées de parenthèses :
L=[42, -81, -12, 31, 82]
s=f"Les négatifs puis les positifs : {sorted(L, key=lambda z:z>=0)}"
print(s)
Les négatifs puis les positifs : [-81, -12, 42, 31, 82]
C’est le même problème pour l’opérateur walrus :
s =f"Le suivant de {(x:=42)} est {x+1}"
print(s)
Le suivant de 42 est 43
Chaînes triples¶
Les f-chaînes et les chaînes brutes sont compatibles :
z="Saut de ligne"
jours = rf"{z} : \n"
print(jours)
jours = fr"{z} : \n"
print(jours)
Saut de ligne : \n
Saut de ligne : \n
Espaces libres dans un champ de remplacement¶
On est libre de placer des espaces dans les expressions entre accolades et de placer des saut de lignes dans une f-chaîne triple, cela n’aurra pas d’influence sur le contenu de la chaîne créée :
nom = "Arthur"
age = 30
s = f"Son nom est {nom} et il a { age + 10 } ans\n"
print(s)
s = f"""Son nom est {nom}.
Il a {age + 10} ans"""
print(s)
Son nom est Arthur et il a 40 ans
Son nom est Arthur.
Il a 40 ans
Justaposition de chaînes littérales¶
Comme pour les chaînes littérales, il est possible de juxtaposer dans du code Python des f-chaînes et des chaînes littérales en les séparant par des espaces sur une même ligne pour obtenir une f-chaîne :
nom = "Arthur"
age= 30
s= "Son " f"nom est {nom}" f"et il a {age+10}" " ans"
print(s)
Son nom est Arthuret il a 40 ans
Toutefois, un champ de remplacement ouvert dans une chaîne littérale juxtaposée doit se refermer dans la même chaîne littérale. Par exemple, le code suivant est invalide :
nom = "Arthur"
age= 30
s= f"Son nom est {nom " f" * 2} et il a {age+10} ans"
print(s)
s= f"Son nom est {nom " f" * 2} et il a {age+10} ans"
^
SyntaxError: f-string: expecting '}'
Divers¶
Les accolades doivent contenir une expression à évaluer :
x=42
s=f"x+1={}"
print(s)
File "a.py", line 2
s=f"x+1={}"
^
SyntaxError: f-string: empty expression not allowed
Il n’est pas interdit qu’une f-chaîne n’ait aucun champ de remplacement :
s=f"Coucou !"
print(s)
Coucou !
Une f-chaîne peut aussi être préfixée par F majuscule :
nom = "Arthur"
age= 30
s= F"Son nom est {nom} et il a {age+10} ans"
print(s)
Son nom est Arthur et il a 40 ans
Largeur d’un champ¶
Fenêtre de champ dans une f-chaîne¶
On souhaite parfois placer un espacement autour d’un champ de remplacement, souvent pour des raisons d’alignement vertical. Par exemple, pour obtenir les chaînes formatées suivantes
1 2 3 | coloration : blanc → noir
taille : gigantesque → minuscule
vitesse : lent → rapide
|
- Lignes 1-3 : on observe que les mots correspondants sont alignés verticalement ainsi que les séparateurs
:et→.
Un gabarit sans spécificateur de formatage permet difficilement d’obtenir le même effet d’alignement vertical :
LL = [["blanc", "noir", "coloration"],
["gigantesque", "minuscule", "taille"],
["lent", "rapide", "vitesse"]]
for L in LL:
s = f"{L[2]} : {L[0]} → {L[1]}"
print(s)
coloration : blanc → noir
taille : gigantesque → minuscule
vitesse : lent → rapide
Maintenant, regardons cet exemple pour illustrer la syntaxe définissant une largeur du champ de remplacement :
fruit = "orange"
print(".....123456789012.....")
s=f".....{fruit:12}....."
print(s)
.....123456789012.....
.....orange .....
On voit, dans la sortie, que la valeur du champ de remplacement, la chaîne orange, est placée dans une « fenêtre » de largeur 12 :
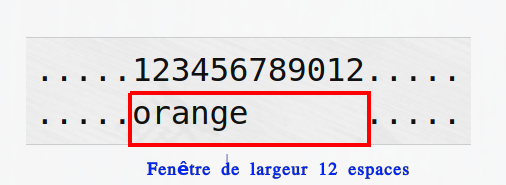
Ainsi, pour placer la valeur d’une expression, disons expr, dans un fenêtre de largeur w, le champ de remplacement à placer dans la f-chaîne aura la syntaxe {expr :w}.
La largeur est le nombre total de caractères de la « fenêtre ». Par défaut, des caractères " " (espace) constituent le « bourrage » de la fenêtre de largeur donnée.
Le formatage présenté tout au début du paragraphe a été obtenu avec le code suivant :
LL = [["blanc", "noir", "coloration"],
["gigantesque", "minuscule", "taille"],
["lent", "rapide", "vitesse"]]
for L in LL:
s = f"{L[2]:10} : {L[0]:12} → {L[1]:1}"
print(s)
coloration : blanc → noir
taille : gigantesque → minuscule
vitesse : lent → rapide
Noter que, parfois, le terme de champ se réfère autant à une valeur de remplacement qu’à l’emplacement de cette valeur dans la chaîne formatée.
Voyons sur un exemple comment le remplissage se fait en fonction de la dimension de l’objet qui remplace :
1 2 3 | for v in ['', "Hello!", "Hello World!"]:
s = f"~~~~~{v:10}~~~~~"
print(s)
|
4 5 6 | ~~~~~ ~~~~~
~~~~~Hello! ~~~~~
~~~~~Hello World!~~~~~
|
- Ligne 2 : un champ de 10 caractères sera inséré.
- Ligne 2 : les tildes servent de ligne-étalon pour comparer avec les lignes suivantes.
- Ligne 6 : le champ est rempli des 6 caractères du mot
Hello!et de 4 espaces (cf. la ligne-étalon) - Ligne 7 : si le remplacement déborde le champ, le remplacement complet est effectué et aucun blanc n’est placé. Dans ce cas, le champ n’a eu aucun effet visible.
Par défaut, chaque élément est placé à gauche du champ. S’il reste de la place dans le champ, le formatage y place des espaces. La largeur du champ est le nombre total de caractères de la fenêtre. Si l’objet à placer dans le champ est plus large que la largeur du champ, l’objet se place normalement et le champ n’est pas visible.
Alignement, remplissage dans une f-chaîne¶
Par défaut, l’alignement est fait au début du champ, c’est-à-dire à gauche. Il est possible de modifier ce comportement en utilisant un des spécificateurs d’alignement > ou ^ :
1 2 3 4 5 6 7 8 9 10 11 12 13 | v = "bonjour"
s = f"----|{v:20}|----"
print(s)
s = f"----|{v:>20}|----"
print(s)
s = f"----|{v:^20}|----"
print(s)
s = f"----|{v:<20}|----"
print(s)
|
14 15 16 17 | ----|bonjour |----
----| bonjour|----
----| bonjour |----
----|bonjour |----
|
- Ligne 3 : rappel du comportement par défaut : alignement à gauche.
- Ligne 6 : spécificateur
>pour obtenr un alignement à droite du champ. - Ligne 9 : spécificateur
^pour obtenr un alignement centré dans le champ - Ligne 12 : par homogénéité, le comportement par défaut a aussi son spécificateur :
<.
Les parties invisibles d’un champ sont, par défaut, remplies de caractères espace.
< est le spécificateur du comportement par défaut.
Remplissage¶
Il est possible de remplir les parties vides d’un champ avec, par exemple, une suite de caractères comme des points (penser à des points de suspension), des tirets, etc. Ainsi :
Nom : .......Nobel........
Prénom : .......Alfred.......
Ce caractère est dit caractère de remplissage. Le caractère de remplissage doit immédiatement suivre le séparateur : et précéder un spécificateur d’alignement.
1 2 3 4 5 6 7 8 9 10 | v = "maintenant"
s = f"hier {v:_<20} demain"
print(s)
s = f"hier {v:_>20} demain"
print(s)
s = f"hier {v:_^20} demain"
print(s)
|
11 12 13 | hier maintenant__________ demain
hier __________maintenant demain
hier _____maintenant_____ demain
|
- Lignes 5 : la spécification de formatage est
_>20donc le remplissage est accompli par le caractère « blanc souligné »_.
Bien que le comportement par défaut soit l’alignement à gauche, le spécificateur < d’alignement à gauche doit être mentionné pour remplir par un autre caractère que l’espace :
v = "bonjour"
s = f"----|{v:_20}|----"
print(s)
s = f"----|{v:_20}|----"
ValueError: Invalid format specifier
Pour disposer d’un champ intact, il suffit de remplir avec le caractère vide :
v = ''
s = f"hier {v:_<20} demain"
print(s)
hier ____________________ demain
Le caractère accolade fermante ne peut être utilisé pour effectuer un remplissage :
v = ''
s = f"hier {v:}}<20} demain"
print(s)
s = f"hier {v:}}<20} demain"
^
SyntaxError: f-string: single '}' is not allowed
Champs pour des nombres dans une f-chaîne¶
Le principe de la fenêtre de champ pour un nombre est le même que pour n’importe quelle chaîne : un nombre (vu comme chaîne de caractères) est placé dans une fenêtre ayant une certain largeur, avec la possibilité de choisir entre un placement à gauche, à droite ou au centre de la fenêtre. Cela permet d’obtenir des effets d’alignement.
1 2 3 4 5 6 7 | x=10
y=2030
z=8
addition=f"{x:>6}\n+{y:>5}\n+{z:>5}\n------\n{x+y+z:>6}"
print(addition)
|
8 9 10 11 12 | 10
+ 2030
+ 8
------
2048
|
- Lignes 5 : tous les nombres sont alignés à droite dans un champ de largeur 6 ou 5 (à cause du signe
+). - Ligne 8-12 : les nombres sont convenablement alignés.
Il était même plus lisible d’utiliser une chaîne triple :
x=10
y=2030
z=8
addition=f"""\
{x:>6}
+{y:>5}
+{z:>5}
------
{x+y+z:>6}"""
print(addition)
Signe et premier chiffre dans une f-chaîne¶
C’est une option de remplissage assez rare d’utilisation et permettant de répéter un caractère entre le signe d’un nombre et son premier chiffre :
1 2 | s = f"____{42:X=9}____{421:X=3}____{-42:X=9}____"
print(s)
|
3 | ____XXXXXXX42____421____-XXXXXX42____
|
- Ligne 1 : par exemple, dans le dernier champ de remplacement
{:X=9}, un champ de largeur 9 est réservé pour placer un nombre ainsi que son signe. L’espace entre le signe éventuel et le premier chiffre du nombre est rempli par des caractèresX. Ainsi, dans notre exemple, moins de 9 caractères vaudront"X", plus précisément, il y en aura 6=9-3 (le nombre-42utilise 3 caractères).
L’usage le plus courant est de placer des zéros. Cet usage tellement usuel qu’il est aussi rendu possible par le spécificateur de type 0n où n est un entier littéral qui indique le nombre total de chiffres à formater :
s = f"Agent {7:0=3}"
print(s)
modele = f"Agent {7:03}"
print(s)
Agent 007
Agent 007
Les nombres¶
Formatage d’un flottant dans une f-chaîne¶
Le spécificateur de formatage le plus usuel pour les flottants est f :
x=22/7
print(x)
s = f"{x}"
print(s)
s = f"{x:f}"
print(s)
3.142857142857143
3.142857142857143
3.142857
Utiliser ce spécificateur f sans rien d’autre est d’intérêt réduit. Le formatage limite la partie décimale a au plus 6 décimales.
La dernière décimale du formatage peut avoir subi un arrondi :
x=3.141592653589793
print(x)
s = f"{x:f}"
print(s)
3.141592653589793
3.141593
Appliquer un formatage flottant à un entier fera apparaître 6 décimales valant toutes 0 :
s = f"{2038:f}"
print(s)
2038.000000
Zéros initiaux dans une f-chaîne¶
Considérons une date telle que 01/09/2030. On observe que le nombre 1 ou le nombre 9 sont précédés d’un chiffre 0. Il existe une option de formatage qui permet de placer un certain nombre de zéros avant un nombre présent dans une chaîne.
Voici un exemple
1 2 | s = f"____{42:09}________{421:02}_______"
print(s)
|
3 | ____000000042________421_______
|
Ligne 1 : la spécificateur
09indique- qu’un champ de 9 caractères de large et destiné à recevoir un nombre est créé
- que le formatage placera le nombre dans le champ et le fera précéder d’autant de zéros que nécessaire pour remplir le champ.
Ligne 3 : si le nombre déborde du champ, aucun zéro n’est placé.
Si le nombre est négatif, les zéros sont placés, comme on s’y attend, entre le signe moins et le premier chiffre :
s = f"____{-42:09}________{-421:02}_______"
print(s)
____-00000042________-421_______
Conversion dans certaines bases dans une f-chaîne¶
Par défaut, les nombres sont formatés en base 10. On souhaite parfois que le nombre soit converti dans l’une des bases suivantes : 2, 8 ou 16. Pour cela il suffit de placer, en dernière position de la spécification de formatage un code de conversion donné dans le tableau suivant :
| Base | Spécificateur | Nom usuel |
| 2 | b |
binaire |
| 8 | o |
octal |
| 10 | d |
décimal |
| 16 | x |
hexadécimal |
| 16 | X |
hexadécimal |
Voici un exemple d’utilisation de chaque spécificateur :
1 2 3 4 5 6 | print(f"{42:b}")
print(f"{42:o}")
print(f"{42:d}")
print(f"{42:}")
print(f"{42:x}")
print(f"{42:X}")
|
7 8 9 10 11 12 | 101010
52
42
42
2a
2A
|
- Lignes 7-12 : noter qu’il n’y a aucune marque dans la chaîne qui montre en quelle base le nombre est représenté.
- Lignes 3 et 4 :le spécificateur
dcorrespond au comportement par défaut et peut être omis. - Lignes 5-6 et 11-12 : noter que la seule différence porte sur la casse majuscule/minuscule des chiffres en lettres.
Le spécificateur x formate les chiffres hexadécimaux sous forme de lettres minuscules (a, b, c, d, e, f) et le spécificateur X formate les chiffres hexadécimaux sous forme de lettres majuscules (A, B, C, D, E, F).
Un spécificateur de conversion doit toujours être le dernier spécificateur (autrement dit, le plus à droite) de la spécification de formatage.
Forme alternée¶
Python (à l’instar de beaucoup de langages) permet de représenter les entiers en base 2, 8 ou 16 sous leur forme littérale (je parle de nombres littéraux, pas de chaînes littérales). Ainsi, voici les nombres littéraux représentant 42 en Python dans ces bases :
b2 = 0b101010
b8 = 0o52
b16 = 0x2a
B16 = 0X2A
print(b2, b8, b16, B16)
42 42 42 42
Comme on le voit ci-dessus, pour représenter 42 par exemple en base 8, on utilise son écriture en base 8, qui est 52 puisque \(\mathtt{5\times 8^1+2\times 8^0=42}\) et que l’on fait précéder du préfixe 0o.
Ainsi, ces représentations utilisent un préfixe commençant par l’entier 0 et un caractère.
Par ailleurs, le formatage de chaînes permet, à partir d’un entier donné, de produire des chaînes littérales représentant cet entier dans les bases ci-dessus. Par exemple, à partir de l’entier 42, on peut produire par formatage la chaîne 0b101010 (b comme binary). Pour cela, on utilise le spécificateur de formatage #. Par exemple, pour 42 et la base 2 :
x = 42
s = f"{x:#b}"
print(s)
0b101010
Le tableau suivant indique les préfixes pour chaînes littérales et les spécificateurs de formatage utilisés en Python :
| Base | Spécificateur | Préfixe |
| 2 | b |
0b |
| 8 | o |
0o |
| 10 | d |
aucun |
| 16 | x |
0x |
| 16 | X |
0X |
- Ligne 2 : pour la base 8, noter que le préfixe n’est pas le préfixe classique (qui est
0et non unominuscule).
Ainsi :
print(f"{42:#b}")
print(f"{42:#o}")
print(f"{42:#d}")
print(f"{42:#x}")
print(f"{42:#X}")
0b101010
0o52
42
0x2a
0X2A
Signalons que lorsque le spécificateur contient le signe #, on le qualifie de forme alternée, cette terminologie vient du C et de Java.
Notation scientifique dans une f-chaîne¶
Python permet de représenter des constantes flottantes avec la notation scientifique stricte, à savoir \(a\times 10^n\) où \(a\) est un flottant, appelé parfois mantisse dont la partie entière au signe près est un flottant entre 1 (inclus) et 10 (exclu).
Le spécificateur de formatage en notation scientifique est e ou E (cette lettre rappelle la première lettre du mot exposant):
print(f"{2030.4248 :f}")
print(f"{2030.4248 :e}")
print(f"{2030.4248 :E}")
2030.424800
2.030425e+03
2.030425E+03
La précision de la mantisse est de 6 décimales. L’exposant est placé dans un champ de 2 chiffres. Le spécificateur e formate la lettre e en minuscule, et le spécificateur E formate en majuscule.
Mettre en relation avec unité sur les nombres littéraux.
Nombre de chiffres¶
Pour formater un nombre en notation scientifique, en utilisant un spécificateur de précision, on peut contrôler le nombre de chiffres significatifs de la mantisse :
print(f"{2030.4248:.2e}")
2.03e+03
Signe + dans une f-chaîne¶
Espace et signe¶
On souhaite parfois obtenir un formatage de nombres comme ci-dessous :
a = -42
b = 2024
- Lignes 1-2 : les nombres
42et2024sont alignés verticalement du côté gauche.
Plus précisément, pour des raisons d’alignement, on souhaite qu’un nombre négatif soit formaté comme on en a l’habitude (unique signe qui précède le premier chiffre) et qu’un nombre positif soit formaté sans signe mais précédé d’un unique espace.
Le code correspondant à l’exemple ci-dessus est :
1 2 3 4 | s=f"a = {-42: }"
t=f"b = {2024: }"
print(s)
print(t)
|
- Lignes 1 ou 2 : le spécificateur consiste seulement en un espace.
Pour placer un espace à la place du signe + devant un nombre, on utilise un spécificateur constitué d’un seul caractère espace qui est donc placé matériellement après le séparateur : et avant l’accolade fermante.
Signe + obligatoire¶
Parfois, on souhaite que le formatage d’un nombre montre toujours le signe + ou - (ce dernier étant obligatoire si le nombre est négatif). Pour cela, il suffit d’utiliser le spécificateur +
s=f"Rennes : {42:+}°C\nMoscou : {-24:+}°C"
print(s)
Rennes : +42°C
Moscou : -24°C
Noter bien qu’un spécificateur de formatage est nécessaire, le code naïf suivant ne fonctionne pas :
1 | print(+42)
|
2 | 42
|
- Ligne 1 : le signe
+est bien présent - Ligne 2 : le signe
+est absent : en effet l’expression+42est évaluée avant d’être affichée.
Séparateur de milliers dans une f-chaîne¶
Pour des raisons de lisibilité, l’usage veut qu’on formate des nombres longs en séparant les chiffres par groupes de trois. Un spécificateur permet cette séparation :
p = -6542120359.4521263
s = f"prix = {p:,} euros"
print(s)
p = 421
s = f"prix = {p:,} euros"
print(s)
prix = -6,542,120,359.4521265 euros
prix = 421 euros
Le spécificateur consiste juste en une virgule :
,
Le séparateur est le séparateur utilisé dans le monde anglo-saxon, à savoir une virgule.
La partie décimale n’est pas formatée par groupe de 3 chiffres et il ne semble pas qu’un spécificateur le permette.
Si le nombre a moins de trois chiffres, aucune action de formatage spécifique n’est réalisée.
Respect des conventions linguistiques¶
Par défaut, le séparateur des chiffres d’un nombre en bloc de trois chiffres est la virgule. L’usage dans les pays francophones est d’utiliser plutôt un espace. Le spécificateur n permet de formater en respectant cet usage. Cela suppose que Python soit installé sur une machine où la locale est francophone.
1 2 3 4 5 6 | import locale
ma_locale = locale.setlocale(locale.LC_ALL, '')
print(ma_locale)
x = 2099.236569633
print(f"{x:n}")
|
7 8 | fr_FR.UTF-8
2 099,24
|
- Lignes 2-3 : chargement de la locale pour toutes les catégories et affichage (ligne 6) de la locale utilisable.
- Ligne 6 : le spécificateur consiste juste en
n - Ligne 8 : on observe la séparation par un espace des deux blocs de chiffres.
La partie décimale a été tronquée à deux chiffres. Même si on tente de garder plus de chiffres significatifs, la partie décimale n’est pas découpée par groupes de 3 chiffres :
1 2 3 4 5 | import locale
ma_locale = locale.setlocale(locale.LC_ALL, '')
x = 2099.236569633
print(f"{x:.10n}")
|
6 | 2 099,23657
|
Pourcentage dans une f-chaîne¶
Le spécificateur % permet de formater un nombre en pourcentage.
print("{:%}".format(3/4))
75.000000%
- On notera que le séparateur décimal est ici un point et non une virgule.
Plus précisément, si \(x\) est le nombre à formater, le formatage consiste :
- à générer en flottant le pourcentage \(100x\)
- à adjoindre le symbole
%.
L’intérêt semble limité.
Avancé, spécialisé ou secondaire¶
Usage de = pour débogage¶
L’exemple ci-dessous va servir d’illustration :
x = 4
s = f"Le nombre { 10 * x + 2 = } est universel"
print(s)
Le nombre 10 * x + 2 = 42 est universel
Depuis Python 3.8, après une expression dans un champ de remplacement, on peut placer un signe =. Ce simple ajout permet un débogage du code car la chaîne contiendra à l’affichage successivement :
- le code Python de l’expression (dans l’exemple, c’est
10 * x + 2) - le signe
= - la valeur de l’expression.
En outre, tous les placements d’espaces autour de l’expression et du signe égal seront rendus à l’identique dans l’affichage. Une fois débogué, il suffit de retirer le signe =, ce qui dans notre exemple donne :
x = 4
s = f"Le nombre { 10 * x + 2 } est universel"
print(s)
Le nombre 42 est universel
et on observe que les espaces entre les accolades sont, cette fois, ignorés.
En outre, l’utilisation de = n’empêche pas de placer une spécification :
x=4
s = f"Le nombre { 10 * x + 2 = :§^20} est universel"
print(s)
Le nombre 10 * x + 2 = §§§§§§§§§42§§§§§§§§§ est universel
Particularité des f-chaînes¶
Une f-chaîne est autant une chaîne que du code. Il n’est pas possible de générer dynamiquement une f-chaîne à partir d’une chaîne arbitraire (ce que l’on qualifierait « d’effifier » une chaîne), à moins d’utiliser eval, voir les discussions ou ressources suivantes :
- How do I convert a string into an f-string?
- How to postpone/defer the evaluation of f-strings?
- PEP 501 – General purpose string interpolation
- What is the name of the internal function that “executes” an f-string?
- way to create fstring inside a fstring
Il est possible de créer un gabarit utilisable par la méthode format qui soit capable de recevoir un nombre arbitraire de champs de remplacement. Par exemple, soit à créer un gabarit qui permette, à partir d’une liste L, de formater une chaîne formée des éléments de L séparés par un tiret et des espaces, par exemple si L vaut
L = ["Mars", "Jupiter", "Uranus", "Neptune"]
alors le formatage attendu est
Mars - Jupiter - Uranus - Neptune
Voici comment créer (et utiliser) un tel gabarit utilisable par la méthode format :
def make_template(L):
return ' - '.join(["{}"]*len(L))
L = ["Mars", "Jupiter", "Uranus", "Neptune"]
template = make_template(L)
print(template)
print(template.format(*L))
{} - {} - {} - {}
Mars - Jupiter - Uranus - Neptune
Pour réaliser la même chose avec des f-chaînes, je vois difficilement comment se passer de la fonction eval :
def make(L):
t=' - '.join([f"{{L[{i}]}}" for i in range(len(L))])
fstring = f'f"{t}"'
print(fstring)
return eval(fstring)
L = ["Mars", "Jupiter", "Uranus", "Neptune"]
print(make(L))
f"{L[0]} - {L[1]} - {L[2]} - {L[3]}"
Mars - Jupiter - Uranus - Neptune
Cumul de spécificateurs dans une f-chaîne¶
Une spécification de formatage peut contenir plusieurs spécificateurs successifs. Voici un exemple commenté :
for x in [1000 * 22/7, 1000 * 333/106]:
s = f"1000 * pi = {x:~^ 20,.2f}"
print(s)
1000 * pi = ~~~~~ 3,142.86~~~~~~
1000 * pi = ~~~~~ 3,141.51~~~~~~
Dans l’exemple, il n’y a qu’un champ de remplacement. Sa spécification est :~^ 20,.2f qui est composée de six spécificateurs :
- un spécificateur de remplissage centré (cf. le spécificateur
^) par des caractères~ - l’espace (résultat : place un unique espace avant un nombre positif)
- un champ de largeur 20
- le séparateur de milliers (spécificateur virgule)
- précision (2 décimales)
- type flottant
L’ordre des spécificateurs n’est pas arbitraire ; de gauche à droite, on trouve des spécificateurs
- d’alignement (
<,^,>et plus rarement=), précédé d’un unique caractère de remplissage - de signe (
+ou espace) - de préfixe de conversion dans certaines bases (
#) - de remplissage par des zéros (
0) - de largeur de champ (un entier)
- de groupement par blocs de 3 chiffres de la partie entière (une virgule)
- de précision (de la forme
.noùnest un entier) - de type (par exemple
f,x,nou%)
Les spécificateurs sont optionnels, certains peuvent être omis (comme le type). Certains spécificateurs ne s’appliquent qu’à des nombres, voire des nombres d’un certain type. La plupart du temps, le bon sens permet de trancher.
La documentation affirme (sans que ce soit très clair : The result (?) is then formatted using …) que la spécification de formatage est identique à celle qu’on utilise avec la méthode format mais la grammaire indiquée pour les f-chaînes ne le reflète pas.
Voici le lien vers la documentation concernant l’ordre des spécificateurs pour la méthode format : Format Specification Mini-Language
Champs emboîtés dans une f-chaîne¶
Considérons la f-chaîne suivante :
s = f"__{x:.>20}____{y:-^10}__"
Voici un exemple d’utilisation de cette f-chaîne :
x, y = 2030, 2038
s = f"__{x:.>20}____{y:-^10}__"
print(s)
__................2030____---2038---__
Décrivons cette f-chaîne. Elle contient deux champs de remplacement, à savoir {x:.>20}__ et {y:-^10} ; ces champs sont séparés. Chacun de ces champs est composé
- de l’expression dont la valeur est à remplacer (
xpuisy) - du séparateur
: - d’une spécification de formatage (
.>20et-^10).
A priori, des champs de remplacement sont toujours séparés. Cependant, il est possible, sous certaines conditions, de placer des champs de remplacement dans une spécification de format :
1 2 3 4 5 | x, y = 2030, 2038
fen1 = ".>20"
fen2 = "-^10"
s = f"__{x:{fen1}}____{y:{fen2}}__"
print(s)
|
- Ligne 4 : le premier champ de remplacement
{x:{fen1}}a une spécification{fen1}qui contient un autre champ de remplacement (cf. les accolades). On parle alors de champs emboîtés.
Action d’un champ emboîté¶
Exécutons l’exemple précédent :
x, y = 2030, 2038
fen1 = ".>20"
fen2 = "-^10"
s = f"__{x:{fen1}}____{y:{fen2}}__"
print(s)
__................2030____---2038---__
On observe que le résultat est le même que la première utilisation de la f-chaîne s ci-dessus. Le processus d’exécution est le suivant :
- tout champ, emboîté ou non, contient une expression. Par exemple, le champ
{fen1}ci-dessus réfère à l’argument".>20", la valeur de la variablefen1; - les champs de remplacement emboîtés sont d’abord remplacés par les arguments correspondants ce qui produit une f-chaîne implicite, ici
"{x:.>20}____{y:-^10}" - suivant le processus habituel, les champs non emboîtés sont remplacés par les expressions qu’ils contiennent.
Intérêt¶
L’intérêt des champs emboîtés est que cela permet de générer des spécificateurs de format dynamiques, par exemple avec des champs de largeur paramétrable.
Un exemple typique, lu dans ce message de forum, permet de paramétrer le nombre de décimales d’un flottant :
1 2 3 | for prec in [0, 3, 6, 9]:
s = f"{22/7:.{prec}f}"
print(s)
|
4 5 6 7 | 3
3.143
3.142857
3.142857143
|
- Ligne 1 : une même f-chaîne va permettre de générer les chaînes de largeur variable (lignes 4-7)
- Ligne 4 : on formate successivement
"{22/7:.0f}", puis"{22/7:.3f}", etc.
On peut faire des formatages plus complexes :
x=2038
for L in [['?', '>', ' ', 42,','], ['~', '^', '+', 20,'e']]:
s = f"__{x:{L[0]}{L[1]}{L[2]}{L[3]}{L[4]}}__"
print(s)
__???????????????????????????????????? 2,038__
__~~~+2.038000e+03~~~~__
Drapeau de conversion dans une f-chaîne¶
Soit le code :
x = "Hello"
y = "Rose"
s = f"{x}{y:.^20}"
print(s)
Hello........Rose........
La f-chaîne f"{x}{y:.^20}" comporte 2 champs de remplacement. Examinons par exemple le 2e champ : {y:.^20}. Il comporte deux composantes :
- l’expression dont la valeur est à remplacer :
y - un spécificateur de formatage :
.^20
Cette syntaxe peut-être enrichie. Pour que mes explications ne soient pas trop abstraites, voici la nouveauté sur un exemple :
x = "Hello"
y = "Rose"
s = f"{x}{y!a:.^20}"
print(s)
qui affiche
Hello.......'Rose'.......
Un champ de remplacement peut disposer, outre une expression et le spécificateur de formatage, d’une troisième composante : un drapeau de conversion. Ce drapeau est placé en 2e position, entre l’expression dont la valeur est à remplacer et avant les deux-points qui précèdent le spécificateur de formatage, cf. ci-dessus, les deux caractères !a.
Un drapeau peut prendre une des trois formes suivantes :
!s ou !r ou !a
Voici un exemple :
x = "Hello"
y = "Rosé"
s = f"{x}{y!s:.^20}"
print(s)
s = f"{x}{y!r:.^20}"
print(s)
s = f"{x}{y!a:.^20}"
print(s)
Hello........Rosé........
Hello.......'Rosé'.......
Hello.....'Ros\xe9'......
Lorqu’un objet X à remplacer est associé à un drapeau de conversion, l’objet X est converti en une chaîne S et c’est la chaîne qui fait l’objet du remplacement. La chaîne S dépend du drapeau :
- si le drapeau est
!salors S eststr(X) - si le drapeau est
!ralors S estrepr(X) - si le drapeau est
!aalors S estascii(X)oùasciiest une fonction de la bibliothèque standard (par exemple, en français, ça réécrit avec un échappement s’il y a un accent).
Dans les cas usuels, le drapeau !s n’a pas d’action :
x = "Hello"
y = "Rosé"
s = f"{x}{y!s:.^20}"
print(s)
s = f"{x}{y:.^20}"
print(s)
Hello........Rosé........
Hello........Rosé........
Il se peut, bien sûr, qu’il n’y ait pas de spécification :
x= "codé"
print(f"C'est {x!a}")
C'est 'cod\xe9'
Exemple avec une liste¶
Montrons un exemple où on veut placer des listes dans des champs de largeur prédéfinie afin d’obtenir un alignement :
[5, 12, 8] est une liste
[50, 120, 80] est une liste
Si on essaye d’obtenir le résultat via le code suivant :
1 2 3 4 5 6 7 | L = [5, 12, 8]
M = [50, 120, 80]
s = f"""{L:13} est une liste
{M:13} est une liste"""
print(s)
|
8 9 | {M:13} est une liste"""
TypeError: unsupported format string passed to list.__format__
|
on obtiendra une erreur. En effet, on essaye d’appliquer une spécification de largeur (lignes 4 et 5) à une liste qui ne la définit pas.
En revanche, si on place un drapeau de conversion, la spécification s’appliquera à une chaîne ce qui a un sens cette fois :
L = [5, 12, 8]
M = [50, 120, 80]
s = f"""{L!s:13} est une liste
{M!s:13} est une liste"""
print(s)
[5, 12, 8] est une liste
[50, 120, 80] est une liste
Troncature dans une f-chaîne¶
On peut vouloir qu’un champ de remplacement reçoive une chaîne dont on ne garde qu’un certain nombre des premiers caractères :
1 2 3 4 5 | semaine=['lundi', 'mardi', 'mercredi', 'jeudi',
'vendredi', 'samedi', 'dimanche']
for i in range(7):
print(f"{semaine[i]:.3} {i + 1}/10/2030")
|
6 7 8 9 10 11 12 | lun 1/10/2030
mar 2/10/2030
mer 3/10/2030
jeu 4/10/2030
ven 5/10/2030
sam 6/10/2030
dim 7/10/2030
|
- Ligne 5 : seuls les 3 premiers caractères du jour de la semaine seront utilisés pour remplacer le champ.
Cette utilisation de troncature semble être assez rare.
La même syntaxe sert à contrôler le nombre de décimales d’un flottant.
Concaténation avec une f-chaîne¶
Le formatage de chaînes permet accessoirement de concaténer ou de joindre des chaînes
a, b, c = "Uni","Ver","Sel"
s = f"{a}{b}{c}"
print(s)
s = f"{a.upper()}-{b.upper()}-{c.upper()}"
print(s)
UniVerSel
UNI-VER-SEL